
Why do LLMs struggle with counting letters in Strawberry 🍓🍓🍓
LLMs can do amazing things, and yet struggle with some basic tasks. Why ?

In the fast-changing world of artificial intelligence, Large Language Models (LLMs) like GPT-4 are doing some pretty amazing things. They can hold complex conversations, write creative stories, help with coding and even handle simple automations. But if you have played around with it, you might have noticed that there’s a surprising twist: these models often struggle with basic tasks, like counting how many times a letter appears in a word. Let’s explore why this happens and what we can learn from this on how LLMs process information.

The curious case of counting letters
Picture this: you ask a high-tech AI, known for crafting eloquent essays and solving tricky problems, a simple question: "How many 'r's are in 'strawberry'?" You’d expect a quick and correct answer, right? But often, LLMs stumble, giving answers like "two" when the right answer is "three."
The screenshot is from the latest Phi4, a 14B parameter, state-of-the-art open model from Microsoft. Here is the Link to run it locally using Ollama and test it out yourself.
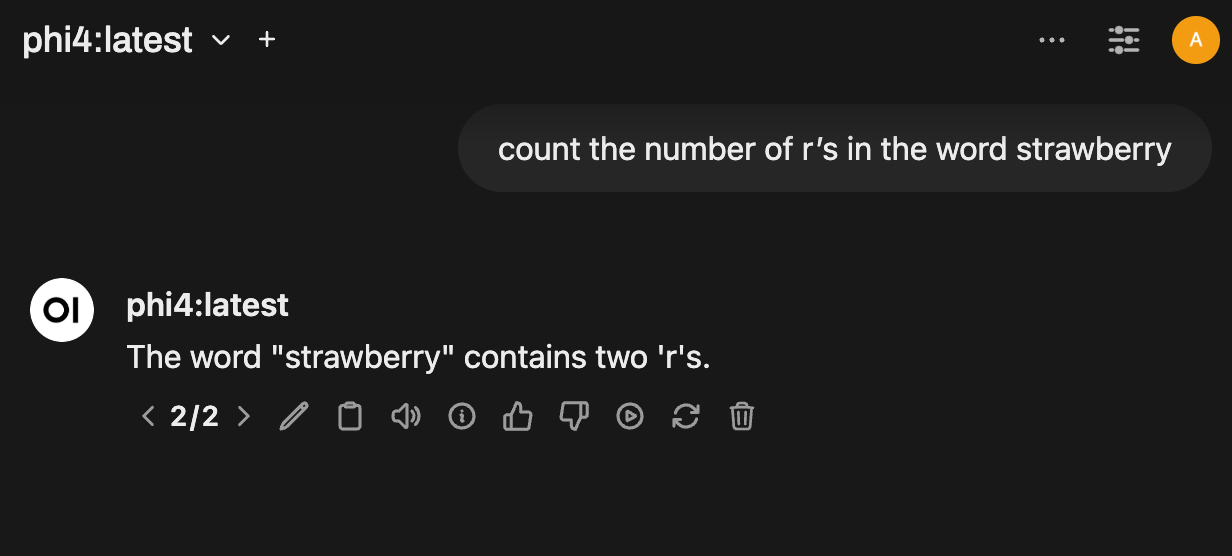
This isn’t just a one-off mistake. These kinds of errors pop up regularly when the models are asked to count letters, especially in words where letters repeat or when the structure is tricky. It's interesting but also a bit concerning that such advanced models can’t handle these simple tasks.
Why Do LLMs Struggle?
To figure out why LLMs have trouble with counting, we need to look at how they’re built and how they process information. Here are a few reasons:
1. Tokenization and Subword Processing
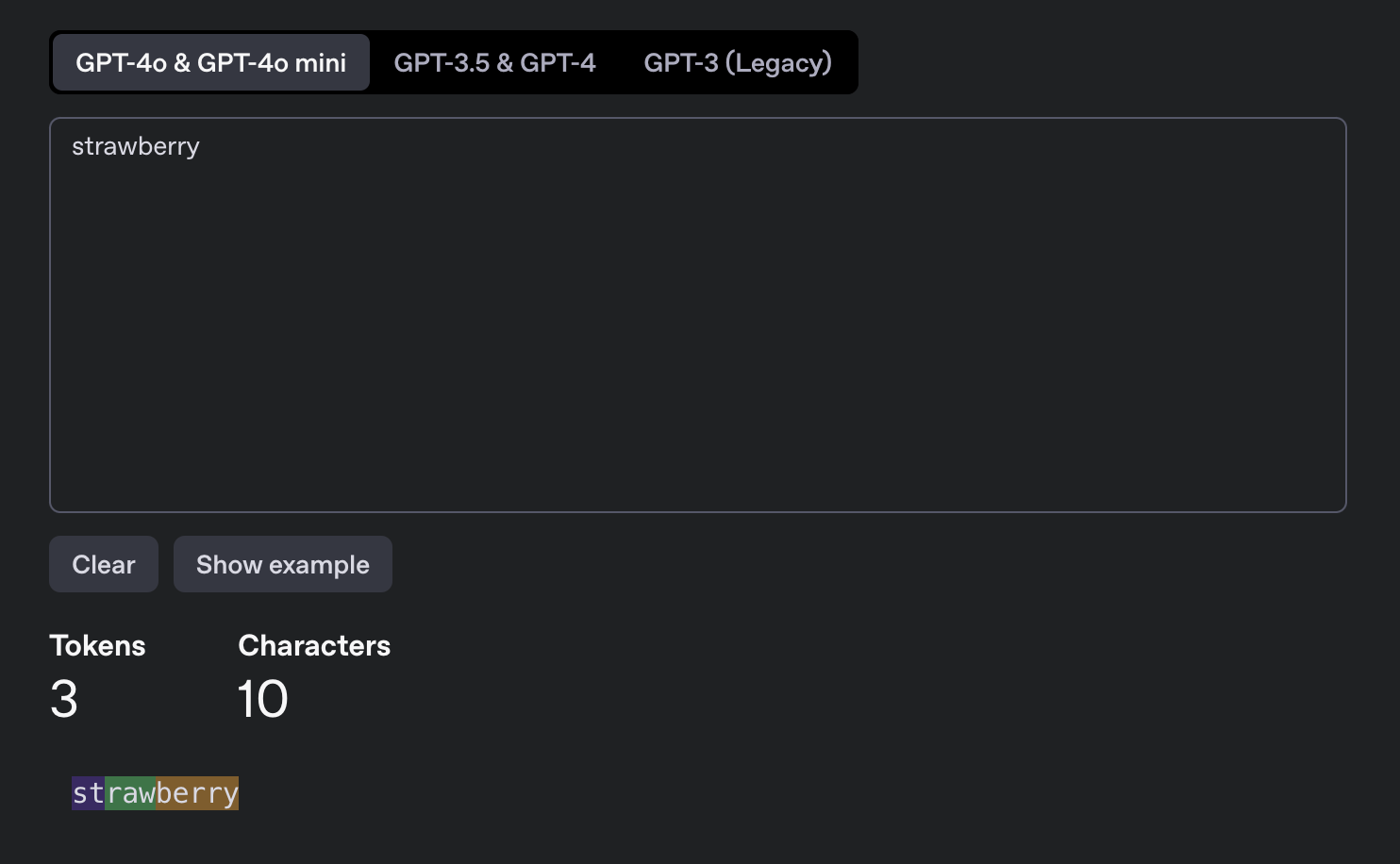
LLMs break down text into tokens, which can be whole words, parts of words, or even punctuation. They often use methods like Byte Pair Encoding (BPE) that combine common letter combinations into single tokens. For example, "strawberry" might be split into "st” “raw" and "berry". This makes language processing faster, but it hides individual letters, making it hard for the model to track them. The model actually sees are a list of numbers curresponding to the tokens and not even the part of words.
You can check OpenAI’s tokenizer here https://platform.openai.com/tokenizer
Further, these tokens get converted to token IDs which is the ID in a dictionary curesponding to that token in the context of this tokenizer
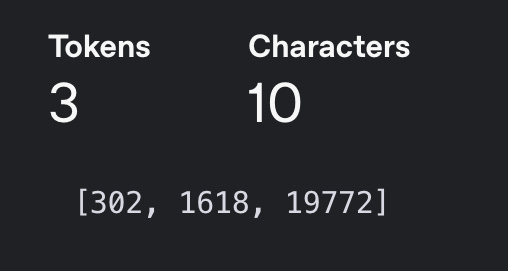
2. Lack of Character-Level Resolution
LLMs operate at token level and not at character level. These models are great at spotting patterns of tokens and predicting what generally comes as next token in a series of tokens. They focus on the big picture of language, but that means they miss out on the tiny details. When you ask them to count letters, they can’t easily zero in on individual characters. It’s like trying to count red cars in a parking lot from way up high—you just can’t see the details.
3. Memory and State Management Limitations
Counting requires keeping track of how many times a letter appears, which means the model needs to maintain an internal counter. LLMs aren’t designed for this level of precise tracking; they’re built more for understanding context and generating text, not for keeping exact counts or doing step-by-step calculations. However this is changing with reasoning LLMs and further with the ability of using tools like a code interpreter.
4. Training Bias Towards Language Tasks
The way LLMs are trained focuses mainly on understanding language patterns and generating text. They learn from huge amounts of text data but don’t really practice tasks that need numerical precision or basic math. So, counting doesn’t get the attention it needs.
Some solutions
Despite these challenges, there are ways to help LLMs do better at counting:
Short-Term Solutions
Explicit Character-Level Prompts: If we break words down into individual letters (like "s t r a w b e r r y"), it can help the model focus on each letter. Giving clear instructions to count can also boost accuracy.
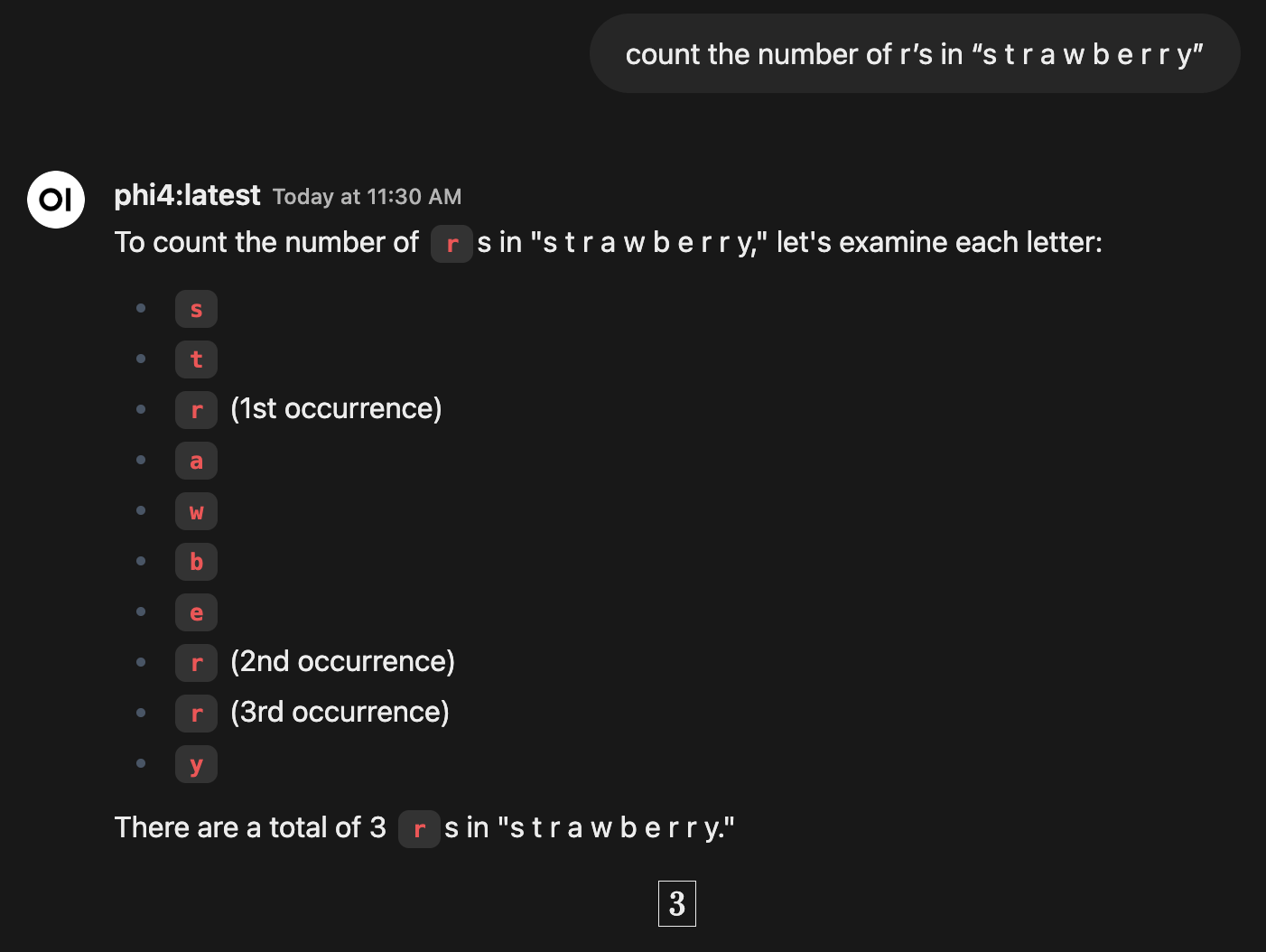
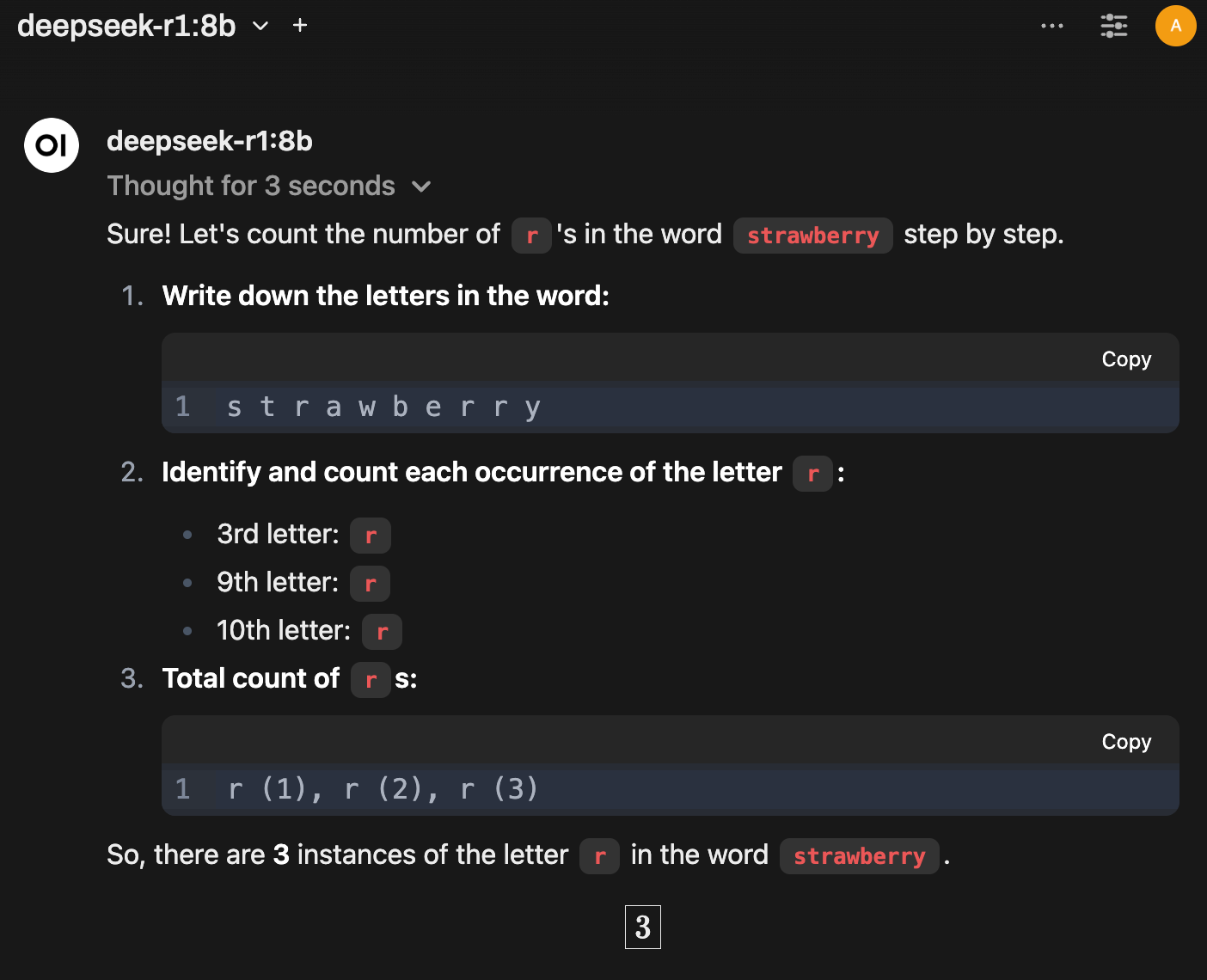
Using reasoning models: Reasoning models do a much better job at these tasks. Even a distilled model like deepseek-r1:8b that is trained on a reasoning model’s output will reasonably handle this task. You can see how the same original prompt gave accurate results.
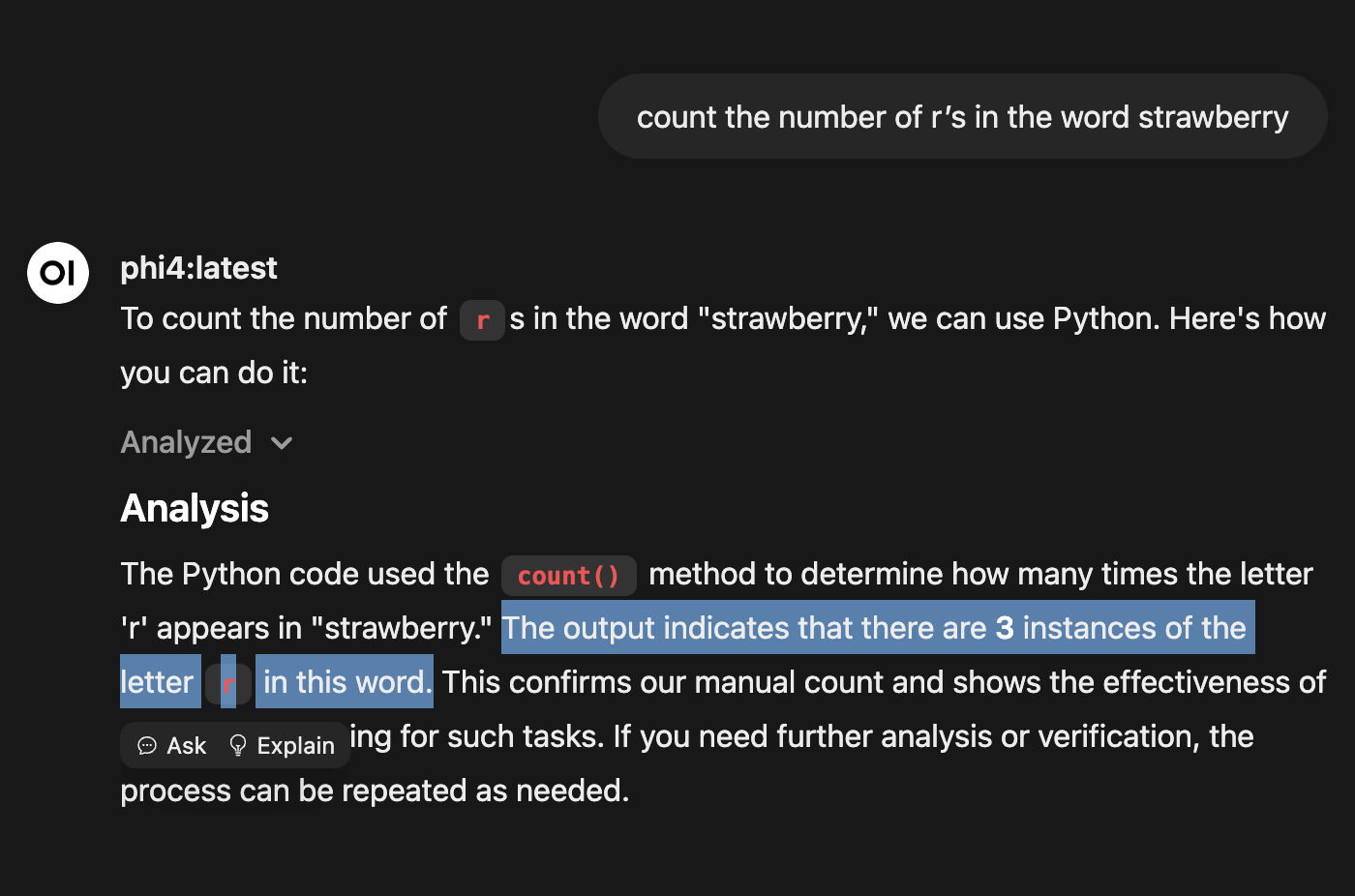
Using Tools: Modern LLM also have tools available to them like a code interpreter. If you ask an LLM to use code such as a python or node interpreter to handle the counting task, you can get consistently accurate results.
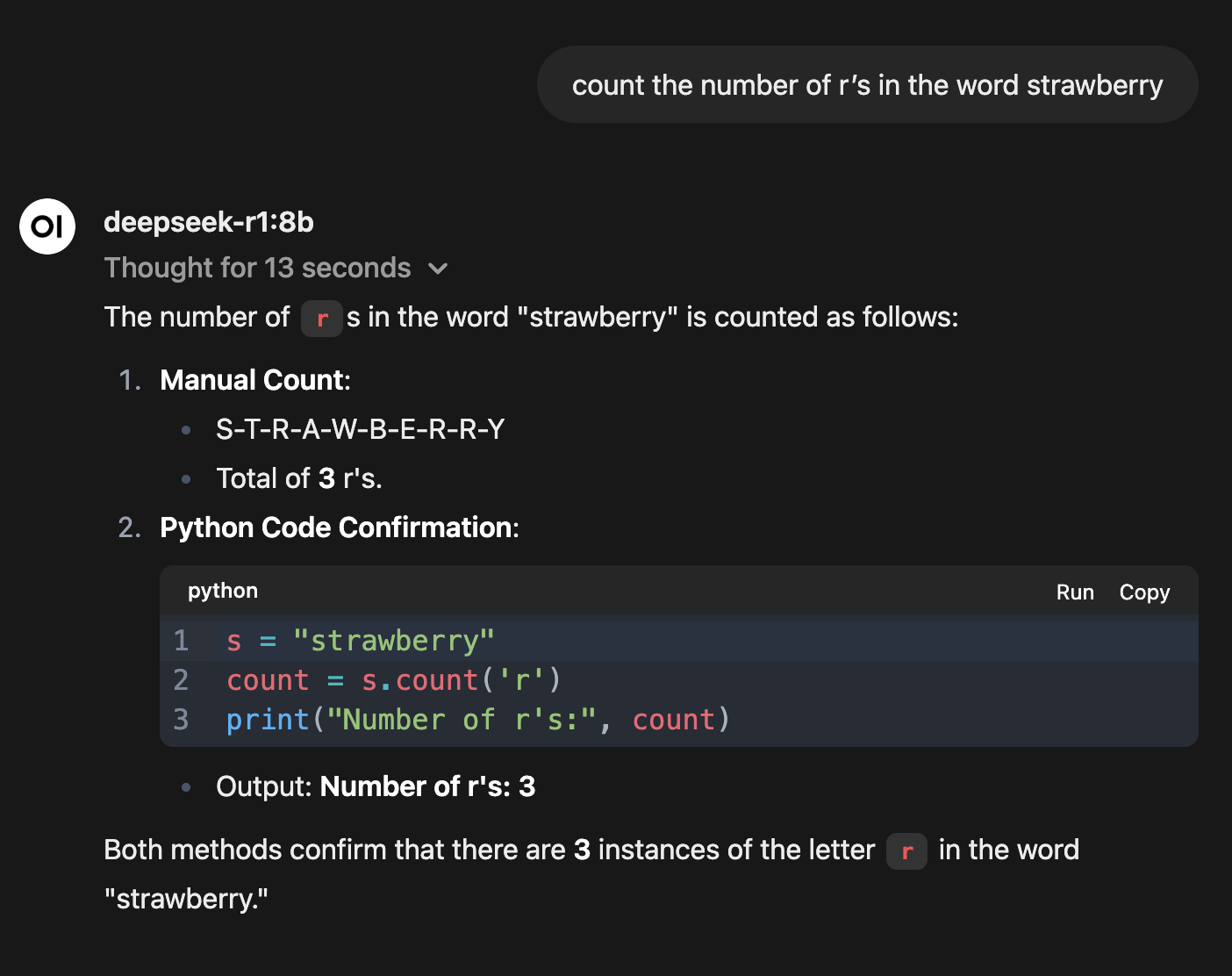
Forcing thought through prompting: You can ask a non reasoning LLM to step through the process of counting by giving it explicit instructions on how to solve the counting problem

Long-Term Solutions
Since counting r’s in strawberry went viral, many of the recent LLM updates have taken care to specifically solve for this type of question. Here are some paths we could see for a more general solution to this problem in the future. Some of these are already being built into LLMs.
Advanced Tokenization Techniques: We could develop new tokenization methods that keep character-level info while still being efficient. This might mean creating flexible tokenization strategies that can adjust based on what’s needed.
Architectural Enhancements: Adding specialized parts to LLMs for tasks like counting or math could help them handle both language and precise computations. Imagine models that can switch between guessing words and doing exact calculations as needed.
Task-Specific Fine-Tuning: We can fine-tune LLMs on datasets made for character-level tasks. This means training them in ways that emphasize precision, which could really enhance their counting skills.
Explainable AI Techniques: Building systems that let users see how the model processes input can help identify counting errors. Understanding how the model works at both token and character levels can lead to more reliable systems.
The Road Ahead
The challenge of getting LLMs to count accurately shows us an important area for improvement in AI. As we keep pushing the limits of what these models can do, it’s crucial to tackle these basic issues.
The best solutions will likely come from a mix of new technologies, better training methods, and smart prompting.
Try this 🍓 problem and the different solutions listed above on every LLM that you have access to and comment below on what you get.