
Understanding LLMs and AGI through the lens of Solomonoff Induction
Solomonoff induction is a theory that describes an optimal method for predicting future data based on past observations. It is a great mental model to understand LLMs and how we could get to AGI.

You might be familiar with Occam's Razor. In simplest terms, Occam's razor states that simpler explanations are more likely to be correct. But then, what is simple to you may not be simple to me. You cannot take Occam’s Razor from philosophy and apply it directly in mathematics. Thats where Solomonoff Induction comes in. It combines the concept of Occam's Razor and a few other interesting concepts formally so that it can be applied in science and maths.
Background
Here is how I got introduced to this concept. Last week, Sam Altman sat down with his team behind GPT 4.5 and had a deep dive discussion on how it was trained. The relevant conversation is below.
Sam Altman:
why does unsupervised learning work?
Dan Selsam:
Compression. So, the ideal intelligence is called Solomonoff induction basically it's uncertain about what universe it's in and it imagines all possible un it considers all possible universes with simple ones more likely than less simple ones and it's fully bayesian in its head and updates its views as it progresses and you can approximate this by finding the the shortest program that computes everything you've
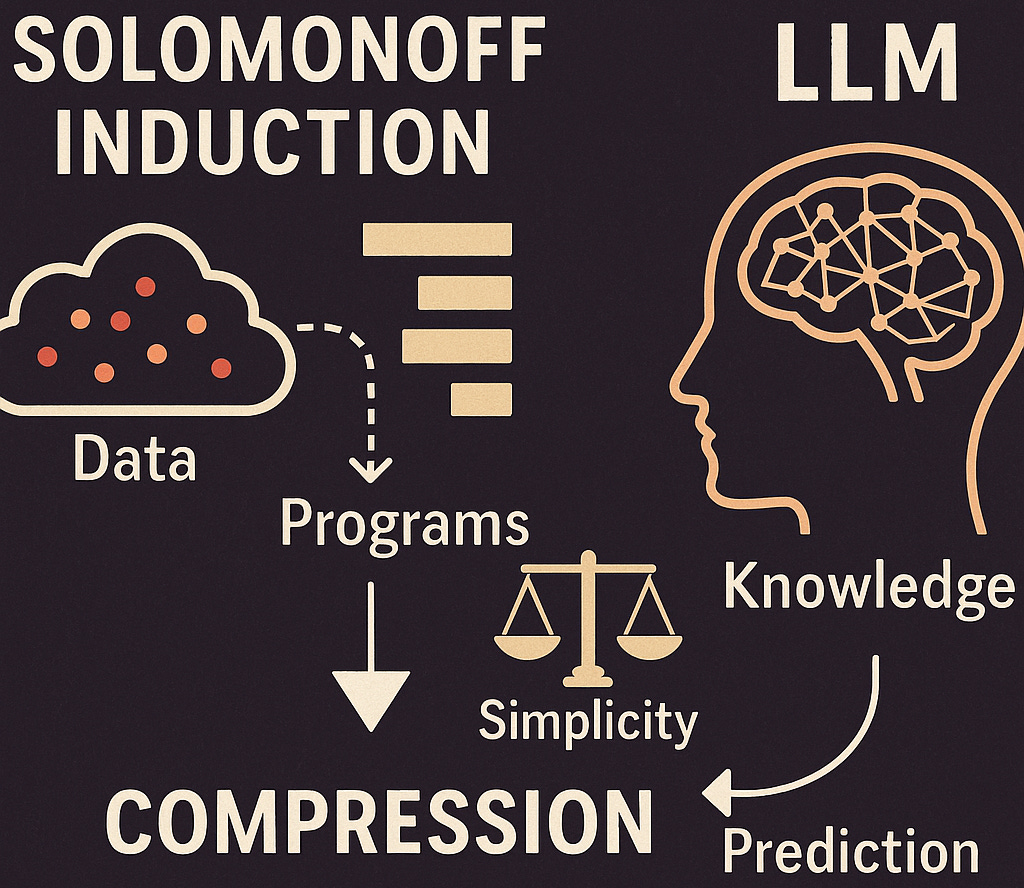
seen so far and what we're doing with pre-training or one way to think about what pre-training is doing is compressing it, trying to find the shortest program that explains all of the data that humans have produced so far as a way of approximating.The whole video is worth watching and is a great behind-the-scenes begins peek into the pre-training of OpenAI's GPT 4.5 model. While this post will focus on Solomonoff induction, I have already shared some key insights from the video as a note earlier on substack.
This got me intrigued on the the concept of Solomonoff induction:
Solomonoff Induction
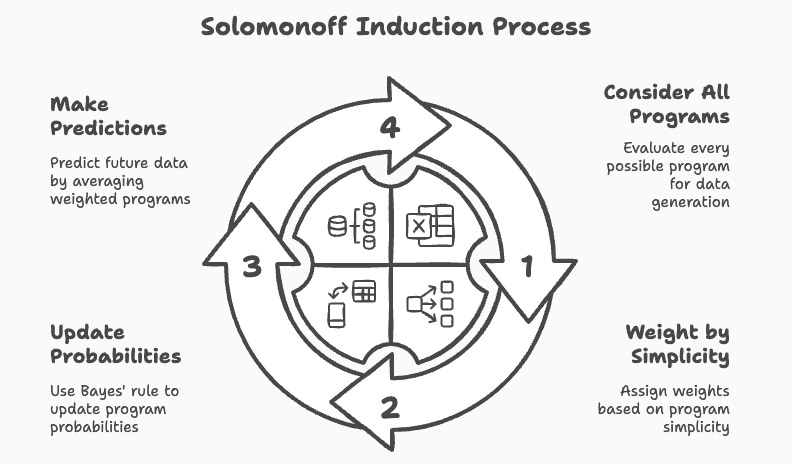
Solomonoff Induction is a mathematical approach to predicting future data based on past observations. It works by considering all possible algorithms that could generate the observed data and assigning higher probabilities to simpler algorithms. This approach is similar to the core idea of Occam's Razor where we say that simpler explanations are more likely to be true. However, the catch is the part that says you have to consider all possible programs/algorithms. This requires infinite compute making it impractical for a direct implementation.
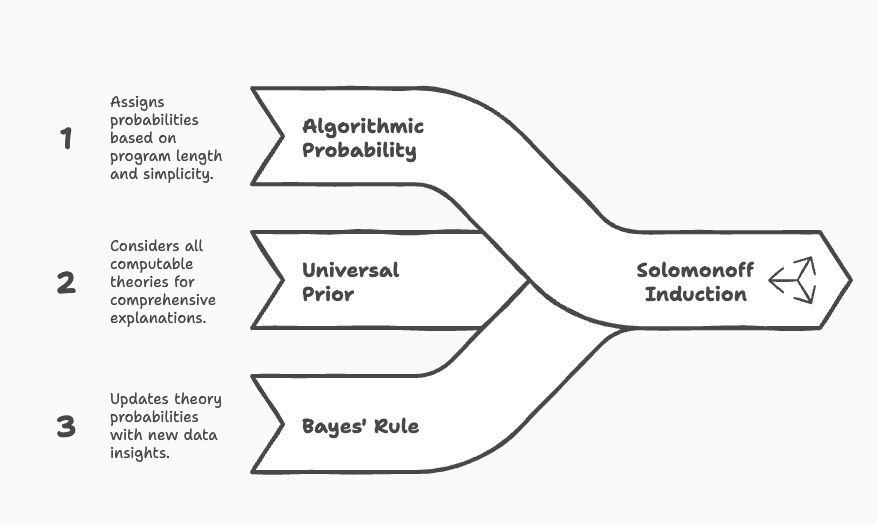
Some of the key concepts under Solomonoff Induction are
Algorithmic Probability which assigns higher probabilities to shorter programs
A Universal Prior probability distribution that assigns a positive probability to any possible solution. This ensures that all possible explanations/solutions are considered.
Bayes' Rule which is used to update the probabilities of theories based on new data.
Now think of LLMs as a way to compress all the knowledge fed into it during the pre-training stage. These models are trained on vast amounts of available data, adjusting its parameters to encode that knowledge.. The ideal outcome of this training phase is to find the simplest (fastest/cheapest/least complex) way to do this encoding. This is where the concept of Solomonoff induction comes in.
Solomonoff induction theoretically considers every possible program that could generate the observed data. It then assigns weights based on simplicity where the shorter programs or the more efficient ones receive the highest weight. As new data comes in, Baye’s rule is used to update the probabilities of each program based on how well it predicts the new data. Future predictions are made by averaging the predictions of all programs, weighted by this updated probability.
Relevance of Solomonoff induction as a mental model
Reinforcement learning - the kind that does not involve human feedback, is currently considered as the primary way to train LLMs and to get us closer to AGI. The relevance of the Solomonoff induction is that it gives a theoretical framework for a universal prediction machine (aka AGI). It gives a way for machines to generalize from limited data.
If we think of Large Language Models as a path to AGI, what we're doing with pre-training is compressing the data given to it and it is trying to find the shortest and most generalizable program that explains the patterns in the data humans have produced so far. It is trying to get to a best way to approximate all of that knowledge. For me, understanding the concept of Solomonoff induction gave me a mental model for understanding this.
Limitations and Final Thoughts
It is important to note that while Solomonoff induction helps us understand the objectives better, it is also an utopian concept in some ways. It is not computable in practice due to requiring consideration of all possible programs. So it ends up more as a theoretical limit or benchmark, rather than a directly implementable method.
Solomonoff induction should only be seen as an effective way to explain the working on LLMs in a metaphoric way. It is not literally doing things like going over all the possible algorithms/solutions and updating bayesian probabilities. It is strictly a mental model.
While we can't implement Solomonoff induction directly due to some of the limitations mentioned above, it gives us a way to understand what an ideal system (AGI) would do. It would prefer simpler, general explanations and refine them with new evidence. LLMs, in a way, emulate this behavior by learning and compressing knowledge from data sets.