
RLSP framework for improved reasoning abilities in LLMs
This paper suggests that the RLSP framework can substantially improve reasoning in LLMs, indicating a promising direction for future AI development.

The emergence of thinking in large language models (LLMs) marks a significant shift in artificial intelligence. With advancements like OpenAI’s new models and Google’s Gemini, these LLMs are evolving into Large Reasoning Models (LRMs). Unlike traditional LLMs, LRMs are capable of reasoning during inference, enhancing output quality through guided search strategies.
To harness this capability, researchers have proposed a framework called Reinforcement Learning via Self-Play (RLSP). This approach consists of three steps: supervised fine-tuning using high-quality demonstrations, employing exploration rewards to encourage diverse reasoning behaviors, and reinforcement learning with outcome verification to ensure correctness. By decoupling exploration and correctness signals during training, the RLSP framework has shown significant improvements in reasoning abilities across multiple models and domains.
Empirical studies reveal that models trained with RLSP can outperform previous methods, demonstrating emergent behaviors such as backtracking and self-correction. For instance, the Llama-3.1-8B-Instruct model improved by 23% on the MATH-500 test set, while Qwen2.5-32B-Instruct saw a 10% boost on AIME 2024 math problems.
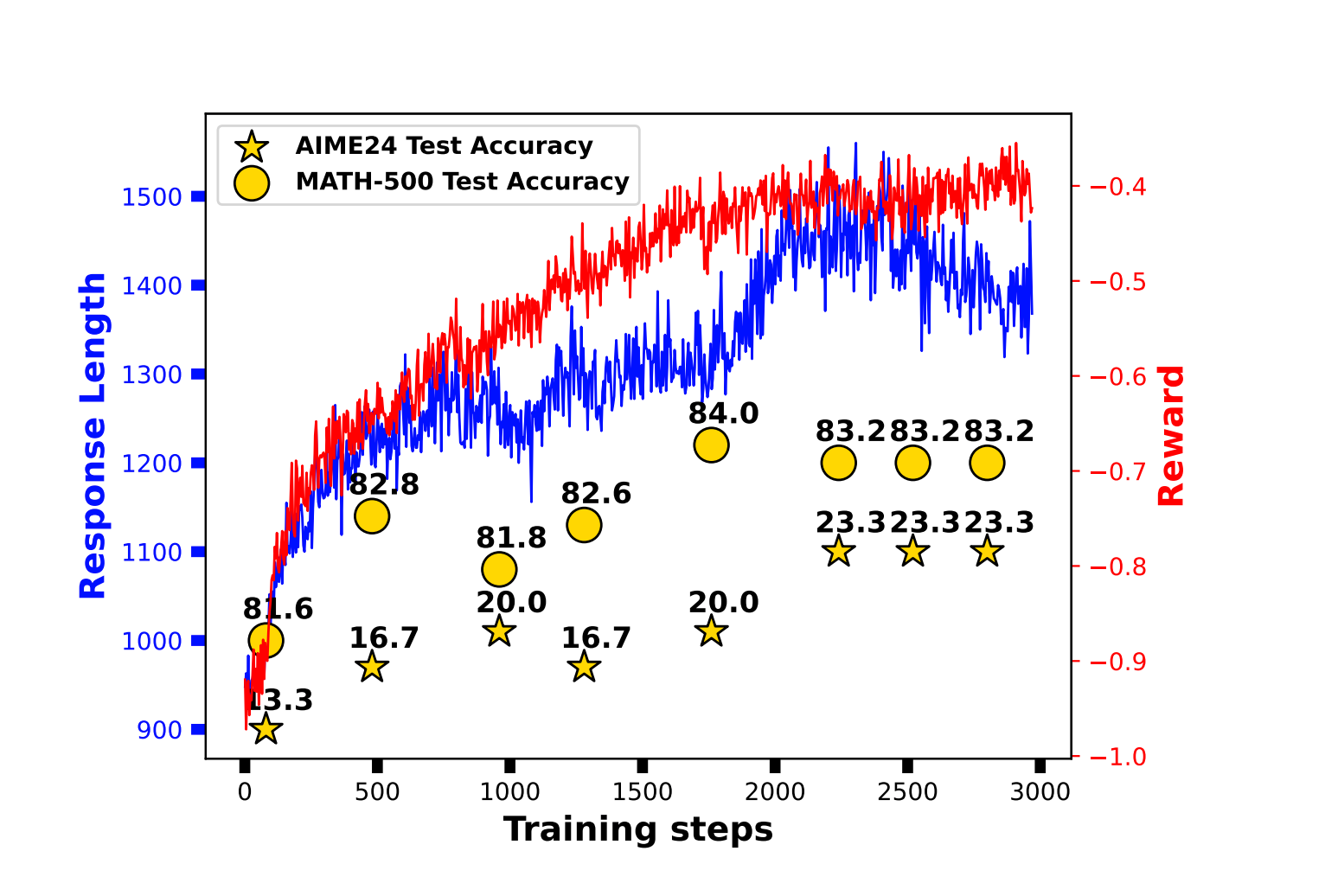
This framework not only enhances problem-solving capabilities but also opens doors for future research on complex reasoning processes in LLMs. By continually refining how we train these models, we can foster a deeper understanding of reasoning in artificial intelligence, potentially leading to breakthroughs that mimic human-like thought processes.
Key Findings:
RLSP framework transforms LLMs into reasoning models.
Performance increased by 23% on MATH-500 test set.
Emergent behaviors include backtracking and verification.
Framework applicable across multiple model sizes and domains.
Exploration rewards enhance reasoning abilities.