


Paperclip vs. FIAT: History's Blueprint for AGI
What did a secret WW2 program get right that another missed entirely? The lessons of Operation Paperclip vs. Operation FIAT offer a surprising historical blueprint in our quest for AGI.

Some History
Operation Paperclip was a secret US program just after the Second World War that brought over 1,600 German scientists, engineers and technicians, (including several with Nazi backgrounds) to the United States. The objective behind the program was to leverage the scientist's expertise in the American military especially in areas like rocket science, nuclear, aerospace and to prevent this knowledge from falling into the Soviet hands during the post war / Cold War period.
Operation FIAT is a lesser known Allied program around the same period (i.e end of the Second World War). Unlike Operation Paperclip that focussed on relocating SMEs, this program was tasked with collecting, evaluating and utilizing Nazi German scientific and industrial advancements by seizing all the documents, equipment and IP.
While the objective of both programs was to replicate the German advancements in science the approaches they took were very different. Paperclip focused on bringing experts to the U.S., while FIAT focused on gathering and disseminating technical information for the benefit of Allied nations.
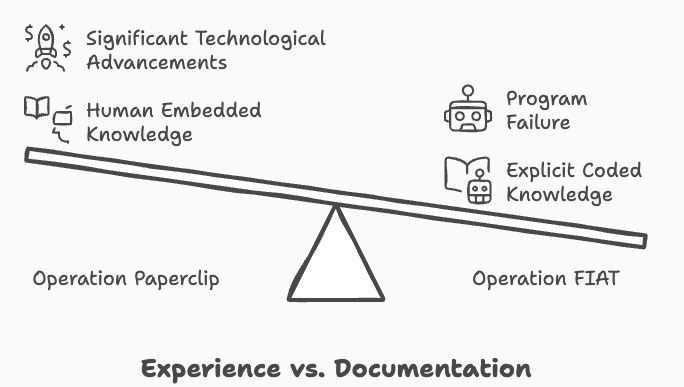
The reason why nobody remembers Operation FIAT is because it was a total failure. Operation Paperclip, however, played a significant role in advancing American military technology, rocket development, nuclear technology and even spaceflight. It led to the creation of NASA's successful Apollo missions to the Moon and gave a significant an advantage to the US in the space race.
The fundamental lesson from the success of Operation Paperclip (and the failure of FIAT) is that the human embedded knowledge that comes from experience, is far more valuable and essential for intelligent breakthroughs than explicit coded knowledge found in documents or technical manuals. Not all of the domain knowledge can be found in books and documentation.
The key to intelligence is knowledge built with experience.
The connection to AGI
So, what does any of this have to do with Artificial General Intelligence or AGI? The popular thought is that large language models LLMs are the path to AGI. So let's, examine that closely.
LLMs are trained on all of the world’s documented knowledge which is mostly in text, images and also in audio / video formats. This includes scientific papers, books as well as user generated content from the internet. In my view, this approach is equivalent to operation FIAT. You will have breakthroughs in language understanding and initial gains, but will stop well short of AGI as it only has encoded knowledge from documented information and lacks knowledge that comes from experience. Below, we will define AGI, and then explain why we cannot get to AGI using LLMs. We will look at one school of thought of getting to AGI using world models. I specifically chose Yann LeCun's vision of world models because it aligns perfectly with the hypothesis made above about experience being the key to intelligence.
Defining AGI
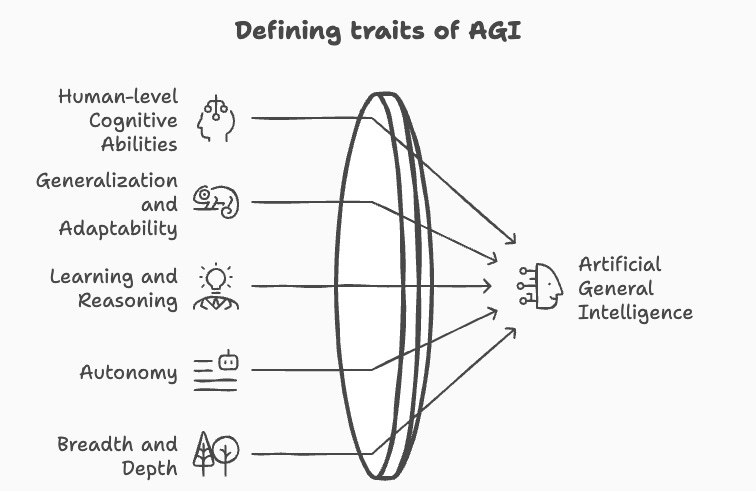
AGI is often confused with super intelligence and hence it is important to set the context by defining what I mean by AGI.
AGI is an AI system that can replace humans in any economic activity involving human intellect. Such a system can understand, learn, and perform any task that a human being can, with proficiency comparable to or surpassing that of a human, across a broad range of domains and without requiring changes to workflows.
Yann LeCun’s views on getting to AGI - world models and JEPPA
Below is is a time stamped video of Meta’s Yann LeCun talking to NVIDIA’s Bill Dally at GTC 2025 about his views on how we will get to AGI. Yann believes that while Large Language Models have achieved impressive feats in language generation and understanding, they are not the path to achieving true Artificial General Intelligence (AGI), or what he calls Advanced Machine Intelligence (AMI)
Some of the important reasons for the limitations of LLMs according to Yann are:
Lack of understanding of the physical world - The real world is much more difficult to deal with than dealing with the language. LLMs trained primarily on text lack the inherent model on how the physical world works. They cannot reason or plan reliably about physical interactions.
Token prediction - LLMs are fundamentally trained to predict the next token in a sequence, based on its training on massive amounts of text data. This only makes them excel or even surpass average human capability at text based tasks like finding patterns in language or things like translation and generation of text.
SOTA reasoning. - While we have reasoning models today, the kind of reasoning they do are very simple. LeCun looks at this as a very simplistic way of viewing reasoning.
Approach doesn't scale efficiently beyond text- Training models to predict every pixel in a video or every token in a sequence is computationally wasteful for learning how the world works. This approach, even when scaled, has failed for tasks like video prediction.
Persistent memory and continuous improvement - Large language models have context windows which are more like ephemeral working memories, but lack persistent long-term memories. They also lack the ability to form understanding of the environment over time, which is crucial for AGI / AMI. Some of the popular large language applications today have included some form of memory, but those are not at the model level and is still relying on external data stores and feeding info into the context at the right time.
So what does he propose? world models and JEPPA.
LeCun proposes architectures based on "world models". He defines a world model as an internal representation of the world that allows a system to predict future states given potential actions. Humans develop these models in the first few months of life to interact with our world. The calls this architecture JEPPA, and the key ideas behind it can be summarized as
Learning abstract representations: Instead of predicting inputs directly (like pixels or tokens), JEPPA learns abstract, latent space representations of the data.
Predicting in abstract space: The model is trained to predict the abstract representation of future data (like the next frame in a video) based on the abstract representation of past data and planned actions, within the latent space.
Energy-Based Models: To distinguish between plausible and implausible configurations in the latent space, LeCun's approaches reply on energy based models to differentiate between the two. This allows the model to capture the constraints of the world without needing to predict every single detail.
Reasoning and Planning: Once a good world model is implemented, the system can perform reasoning and planning by imagining a sequence of actions and using its internal world model to predict the resulting future state, selecting actions that lead to desirable outcomes.
Yann LeCun sees the current LLM approach as limited by its focus on discrete tokens and input-level prediction. This struggles to capture the continuous, causal nature of the physical world required for truly intelligent reasoning and planning. He advocates for architectures like JEPPA that learn and manipulate abstract, compact representations of reality, enabling more efficient and robust world modeling, which he believes is the necessary step towards building advanced machine intelligence. He advocates for a experience lead approach to model reality and learning from it.
Role of Quantum Computing:
Role of Quantum Computing: Quantum computing has made some serious progress recently and is expected to be useful in practical applications in a few years. I feel that you cannot model real world accurately without quantum processors working in tandem with GPUs. The paths of AI and Quantum will converge and lead to realistic world models that can train AGI.
The paths of AI and Quantum will converge and lead to realistic world models that can train AGI.
Some of the key reasons for this conviction are
At its most fundamental level, the real world operates according to the laws of quantum mechanics.
Yann LeCun’s vision for AGI/AMI, relies on building and reasoning with a world model that captures the underlying dynamics of the real world.
One of the key reasons for LeCun’s argument against LLMs' for AGI is the reliance on discrete tokens for modeling the continuous physical world. Quantum is a better approach to model a continuous physical world.
A hybrid approach where GPUs handle a lot of the heavy data processing tasks and leverage QPUs (Quantum processing units) for real world reasoning tasks that cannot be modeled on traditional systems could lead to superior models.
Concluding Thoughts
I have tried to draw a parallel between the historical outcomes of the post WW2 Operation Paperclip and Operation FIAT, that suggests a fundamental truth about the nature of intelligence. Intelligence lies in deep, embedded knowledge gained through experience and interactions, and relying solely on documented information cannot replicate it. While Generative AI and specifically Large Language Models represent an extraordinary leap in AI (analogous to operation FIAT), the path to true Artificial General Intelligence (AGI) may be hindered by this very dependency on documented information.
The vision put forth by researchers like Yann LeCun, centered on sophisticated world models that learn by engaging with reality, aligns compellingly with the "Paperclip principle" that prioritizes experiential understanding. Combined with the potential of quantum computing to accurately model the continuous complexities of the physical world, this experience-driven approach offers a promising blueprint for building AGI than simply refining data-centric paradigms.
Ultimately, achieving human-level intelligence may require us to move beyond the world's vast digital library and focus on teaching machines to truly learn from the world itself. All the pieces of the AGI puzzle may be finally coming together.