
Context Bloat in Large Language Models
Context makes or breaks large language model implementations.


LLMs have a limited amount of data they can process in one time, which is known as their context length. Context length has increased exponentially alongside model intelligence and capability. The largest state-of-the-art models today have millions of tokens in context length. While that allows a lot more tokens or context to be stored during inference, there are also problems that comes with it. The more context a model holds, the harder it becomes to understand what is important for the current task. This is referred to as Context Bloat.
There is some research from Stanford that shows LLMs get lost when the context becomes too long. Lost in the Middle: How Language Models Use Long Contexts (https://arxiv.org/abs/2307.03172)
The effect of this can be clearly seen while implementing Agentic AI systems. Anthropic recently published a very detailed technical blog on the design of their agentic deep research platform. One of the things that caught my eye was their comparison of multi-agent system and single-agent system for their agentic research.
Source: https://www.anthropic.com/engineering/built-multi-agent-research-system
“We found that a multi-agent system with Claude Opus 4 as the lead agent and Claude Sonnet 4 subagents outperformed single-agent Claude Opus 4 by 90.2% on our internal research eval. For example, when asked to identify all the board members of the companies in the Information Technology S&P 500, the multi-agent system found the correct answers by decomposing this into tasks for subagents, while the single agent system failed to find the answer with slow, sequential searches.”
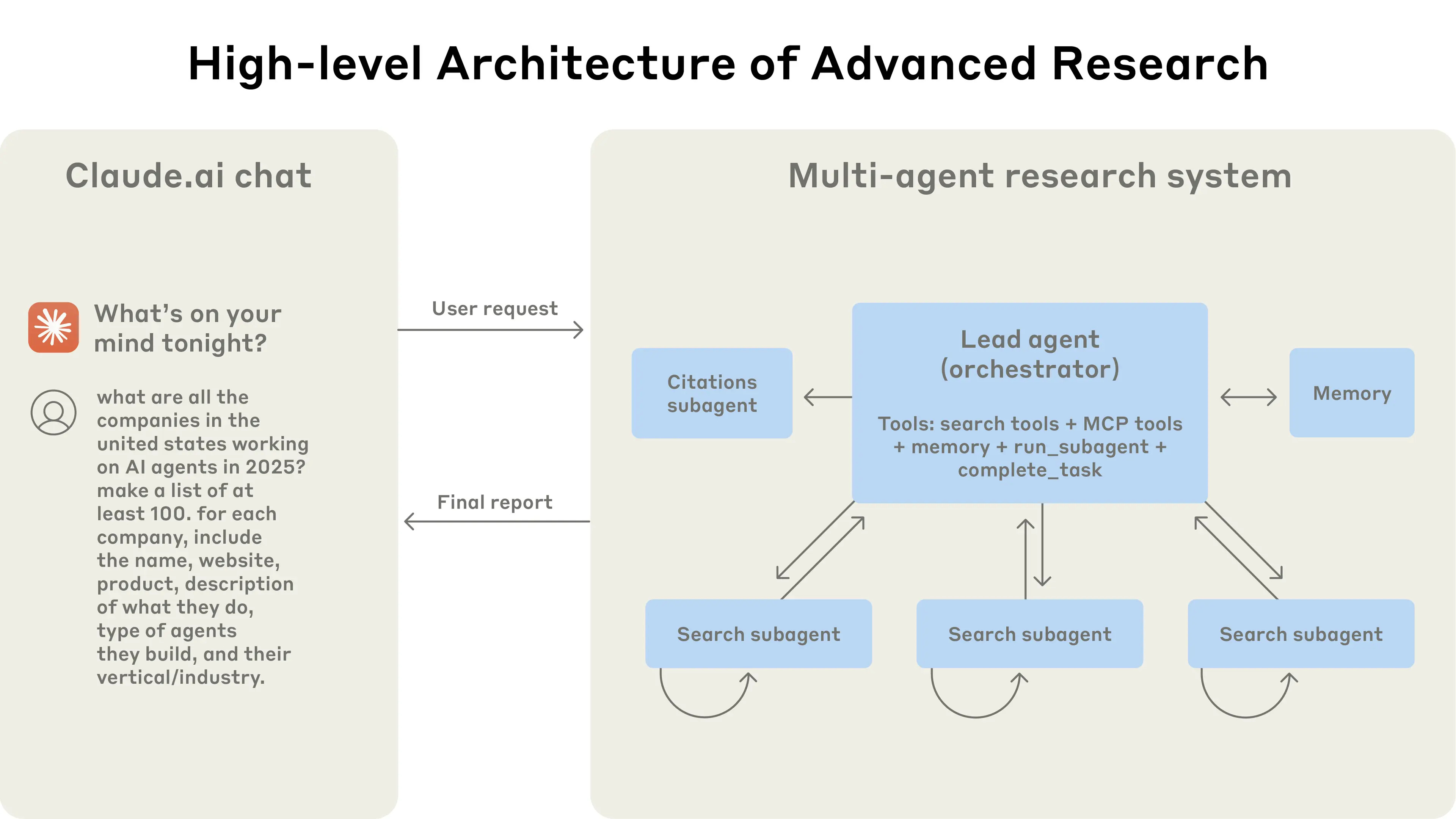
One of the main reasons why a single-agent system fails is due to its inability to stay on course as the context gets filled. The more context a model holds, the harder it becomes to distinguish what is important for the current task. A multi-agent system, however, has clear separation of responsibilities and use specialized agents to carry out sub-tasks. The entire process is orchestrated through a lead agent which is a far more powerful reasoning model. Multi-agent systems are also super expensive as the same research from anthropic notes that it consumes 15 times more tokens as compared to a normal chat session with AI.
It would have been great if there was a Java garbage collection type of system that will continuously clean the context of these large language models. There is a lot of research going on to solve this problem. Some of the research approaches are:
Attention Filtering:
Models use attention mechanisms to focus only on the most relevant details, ignoring the rest. Attention-based filtering helps mitigate “recency bias” and efficiently prioritize long-range dependencies.
Reference: Attention Sorting Combats Recency Bias in Long Contexts https://arxiv.org/pdf/2310.01427.pdf
Garbage Collection for Context:
Inspired by software memory management, “learned garbage collection” techniques apply reinforcement learning to dynamically discard irrelevant or older information from the model’s context.
Reference: Learned Garbage Collection - DSpace@MIT https://dspace.mit.edu/bitstream/handle/1721.1/132291.3/3394450.3397469.pdf
As the industry pushes language models toward longer context windows, it is clear that “context bloat” is not a bug, but a reality of transformer architectures and agentic workflows. Practical solution is to therefore working with this constraint. It is easy to get carried away with RAG and MCP and fill the context window. Currently the safest design choice is to treat context as a scarce resource and curate aggressively, retrieve precisely, and monitor relentlessly for drift through evals so that every token you pay works for you.