
Chain of Draft - a novel approach to improving CoT
This paper presents Chain of Draft, a method for LLMs that enhances efficiency by generating concise intermediate outputs, reducing costs and latency.

Background
Chain of Thought (CoT) is a widely used technique for improving reasoning in LLMs, particularly in complex multi-step problems. It works by breaking problems into intermediate reasoning steps, making the model’s decision-making more interpretable. Some models, like DeepSeek, tend to display intermediate reasoning steps more explicitly, while others, like OpenAI’s O series models and Grok, tend summarize them .
However, CoT can be verbose, increasing token usage, latency, and computational cost. While I personally enjoy seeing the model’s step-by-step reasoning, many users and most applications prefer faster and more cost-effective responses. This is where an alternative approach, Chain of Draft (CoD), comes in. The promise of CoD is improved efficiency by minimizing verbosity while preserving accuracy. Authors claim this mimics human reasoning better than CoT
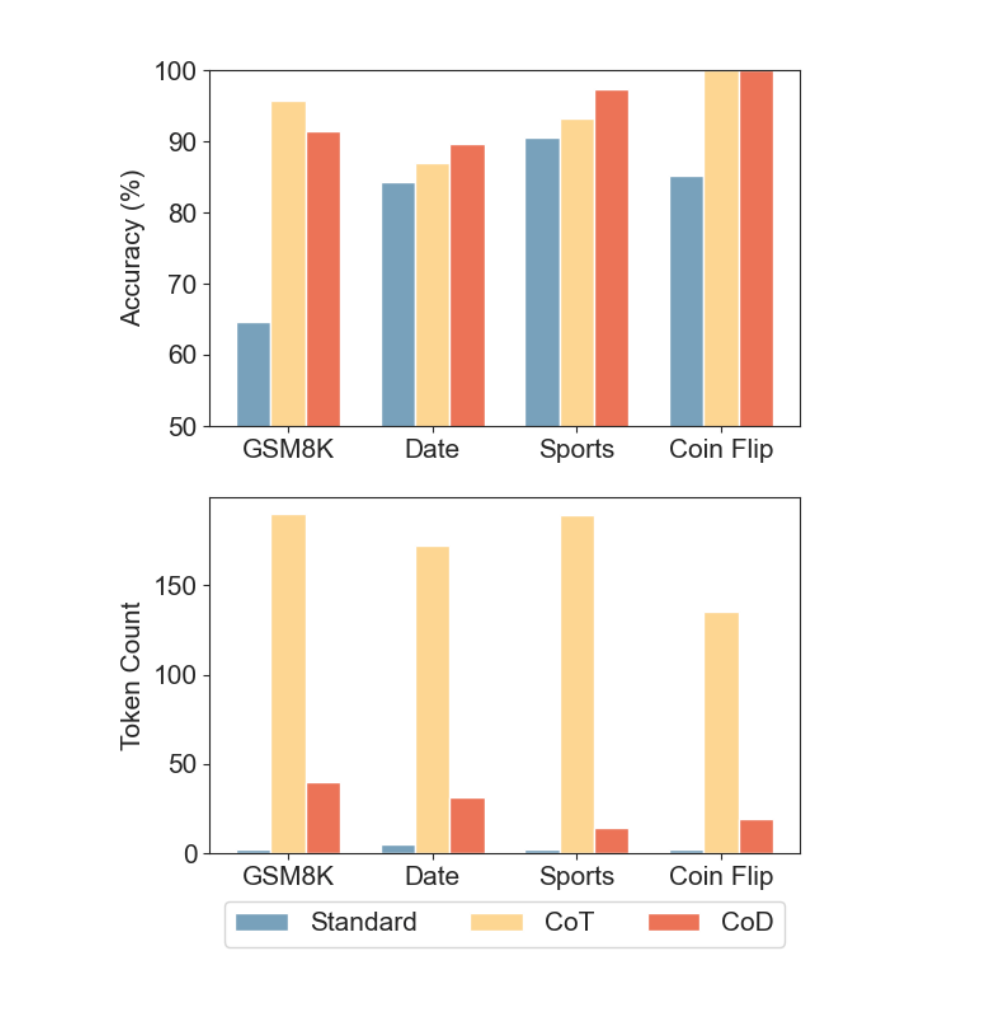
Results: Comparison of Claude 3.5 Sonnet’s accuracy and token usage across different tasks with three different prompt strategies: direct answer (Standard), Chain of Thought (CoT), and Chain of Draft (CoD). CoD achieves similar accuracy as CoT while using significant fewer tokens.
Overview of CoD
At its core, CoD is all about cutting the fluff. It claims to reduce verbosity without compromising the reasoning accuracy we expect from LLMs. CoD operates on just 7.6% of the tokens used in the previous Chain of Thought (CoT) method. That’s a significant decrease. Less token usage means faster processing times and cost, which is a game-changer for real-world applications.
The study put CoD through its paces, comparing it against standard prompting techniques and the CoT method across a range of tasks—arithmetic, common sense, and symbolic reasoning. Two LLMs, GPT-4o and Claude 3.5 Sonnet, were evaluated using various datasets, including GSM8k and BIG-bench. The results were promising, showing that CoD consistently performed as well as or better than CoT in terms of accuracy (in most cases), while significantly decreasing latency (in all cases).
I am not sure if we have all the detail in the paper to reproduce the results, but CoD looks like a promising option to consider. CoD could transform how we think about LLM efficiency. It promises not just faster models, but ones that are more practical for real-world applications.
Appendix with examples:
System Prompts:

Models used : GPT-4o (gpt-4o-2024-08- 06) from OpenAI and Claude 3.5 Sonnet (claude3-5-sonnet-20240620) from Anthropic
Sample Output:
Prompt: Jason had 20 lollipops. He gave Denny some lollipops. Now Jason has 12 lollipops. How many lollipops did Jason give to Denny?

